序列设计¶
序列设计是生成与给定蛋白质/抗体结构相兼容的序列的任务。这在医学(例如药物设计)和生物技术(例如新型酶的设计)中具有重要意义。
功能亮点¶
- 经验证的算法:支持已被实验验证、受到广泛使用的蛋白序列设计算法 ProteinMPNN。经微调后可以用抗体序列设计。
- 云端批量设计:该算法部署在我们的云平台上,并可针对一个结构批量设计多条序列,进而能够大规模运行。算法设计的结果以 csv 格式储存,方便导出。
输入¶
要提交序列设计任务,请打开项目编辑器,并从“设计”下拉菜单中选择“序列设计”。
- Target(目标):序列设计的目标结构。
- Structure(结构):以 PDB/mmCIF 格式表示的目标结构。结构可以从本地机器上传,从云数据库导入或通过 GeoBiologics 任务生成。
- Chains to design(要设计的链):所设计的链的 ID。如果未指定,则将设计所有链。
- Job Name(任务名称):任务的名称。请注意,任务名称必须在项目内唯一。

模型 & 参数¶
您可以使用通用蛋白序列设计模型 ProteinMPNN 或长于抗体序列设计 ProteinMPNN-Ab 模型运行本任务。
两个模型的参数相同,如下所示:
- # designs (生成的设计数量): 要生成的序列数量。默认值为 10。
结果¶
在文件与任务管理器面板中点击任务结果,查看任务结果。
结果存储在 CSV 文件中,可以通过点击结果表格右上角的"![]() "按钮下载。
"按钮下载。
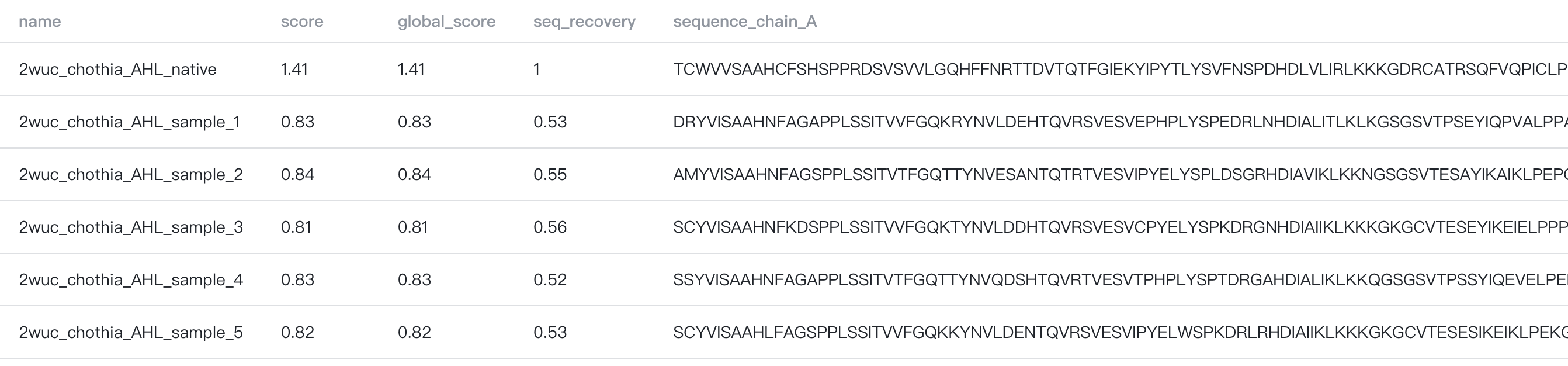
结果表格包含以下列:
- name: 输出序列的名称
- score: 采样(已设计)氨基酸的平均负对数似然(average negative log likelihood)
- global_score:所有链中氨基酸的平均负对数似然(average negative log likelihood)
- seq_recovery: 设计序列与输入序列之间的平均序列一致性(sequence identity)
- sequence_chain_{chain_id}: 链 {chain_id} 的设计序列。例如,如果您选择 H,L 作为要设计的链,结果表格中将有两列,
sequence_chain_H和sequence_chain_L